SEO Audits are a core service I provide, including both comprehensive audits and laser-focused audits tied to algorithm updates. There are times during those audits that I come across strange pages that are indexed, or I see crawl errors for pages not readily apparent on the site itself. As part of the investigation, it’s smart to analyze and crawl a website’s xml sitemap(s) to determine if that could be part of the problem. It’s not uncommon for a sitemap to contain old pages, pages leading to 404s, application errors, redirects, etc. And you definitely don’t want to submit “dirty sitemaps” to the engines.
What’s a Dirty Sitemap?
A dirty sitemap is an xml sitemap that contains 404s, 302s, 500s, etc. Note, those are header response codes. A 200 code is ok, while the others signal various errors or redirects. Since the engines will retrieve your sitemap and crawl your urls, you definitely don’t want to feed them errors. Instead, you want your xml sitemaps to contain canonical urls on your site, and urls that resolve with a 200 code. Duane Forrester from Bing was on record saying that they have very little tolerance for “dirt in a sitemap”. And Google has explained that xml sitemaps are the second most important source for url discovery. Therefore, you should avoid dirty sitemaps so the engines can build trust in that sitemap (versus having the engines encounter 404s, 302s, 500s, etc.)
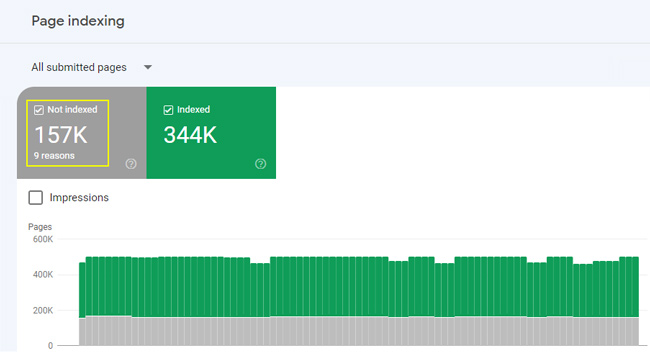
Indexed to Submitted Ratio
One metric that can help you understand if your xml sitemaps are problematic (or dirty) is the indexed to submitted ratio, which you can understand via Google Search Console. When you access the Sitemaps section of webmaster tools under the left-side Indexing menu in GSC, you will see the number of pages submitted in the sitemap, but also the number indexed. That ratio should be close(r) to 1:1. If you see a low indexed-to-submitted ratio, then that could flag an issue with the urls you are submitting in your sitemap. For example, if you see 12,000 pages submitted, but only 6,500 indexed, then that’s only 54% of the pages submitted.
Here’s a screenshot showing 157K urls being submitted, but not being indexed for some reason: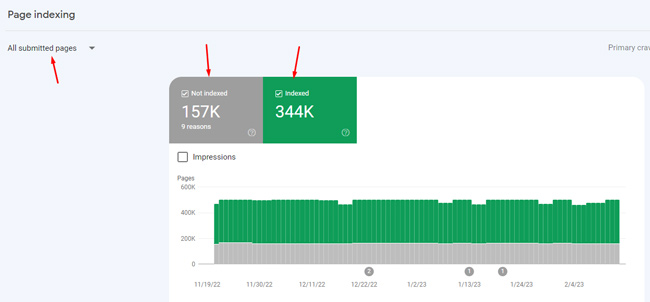
Pages “Linked From” in Google Search Console
In addition to what I explained above about the indexed to submitted ratio, you might find crawl errors in Google Search Console for urls that don’t look familiar. In order to help track down the problematic urls, Search Console will show you how it found the urls in question.
If you inspect the url in GSC, you will see the error details. But, you will also see the referring urls where Google found links to the url and the sitemaps that contain the urls. That information can reveal if the urls are contained in a specific sitemap, and if the urls are being linked to from other files on your site. This is a great way to hunt down problems, and as you can guess, you might find that your xml sitemap is causing problems.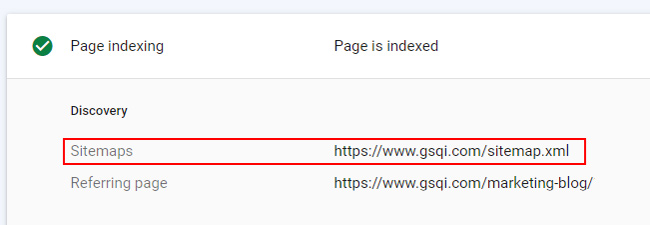
Crawling XML Sitemaps
If you do see a problematic indexed-to-submitted ratio, what can you do? Well, the beautiful part about xml sitemaps is that they are public. As long as you know where they reside, you can download and crawl them using a tool like Screaming Frog. I’ve written about Screaming Frog in the past, and it’s a phenomenal tool for crawling websites, flagging errors, analyzing optimization, etc. I highly recommend using it.
Screaming Frog provides functionality for crawling text files (containing a list of urls), but not an xml file (which is the format of xml sitemaps submitted to the engines). That’s a problem if you simply download the xml file to your computer. In order to get that sitemap file into a format that can be crawled by Screaming Frog, you’ll need to first import that file into Excel, and then copy the urls to a text file. Then you can crawl the file.
And that’s exactly what I’m going to show you in this tutorial. Once you crawl the xml sitemap, you might find a boatload of issues that can be quickly resolved. And when you are hunting down problems SEO-wise, any problem you can identify and fix quickly is a win. Let’s begin.
Update: Screaming Frog now lets you crawl XML sitemaps directly from the tool. So if you are just trying to crawl a sitemap, then just enter “List Mode” and select the option to download an xml sitemap. Then just enter the url for the sitemap. If you want to download the sitemap, then follow the instructions below.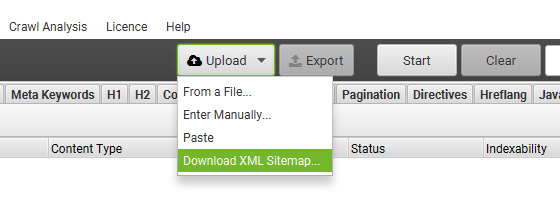
Quick Note: If you control the creation of your xml sitemaps, then you obviously don’t need to download them from the site. That said, the sitemaps residing on your website are what the engines crawl. If your CMS is generating your sitemaps on the fly, then it’s valuable to use the exact sitemaps sitting on your servers. So even though you might have them locally, I would still go through the process of downloading them from your website via the tutorial below.
How To Download and Crawl Your XML Sitemaps
- Download the XML Sitemap(s)
Enter the URL of your xml sitemap, or the sitemap index file. A sitemap index file contains the urls of all of your xml sitemaps (if you need to use more than one due to sitemap size limitations). If you are using a sitemap index file, then you will need to download each xml sitemap separately. Then you can either crawl each one separately or combine the urls into one master text file. After the sitemap loads in your browser, depending on the browser, you can just click “File”, and then “Save As”. For example, that’s how it works in Firefox. Then save the file to your hard drive. And if you are using Chrome, then just right click in the window containing your sitemap and select “Save As”. Then just save the xml sitemap to your computer.
- Import the Sitemap into Excel
Next, you’ll need to get a straight list of urls to crawl from the sitemap. In order to do this, I recommend using the “Import XML” functionality in the “Developer” tab in Excel. Click “Import” and then select the sitemap file you just downloaded. After clicking the “Import” button after selecting your file, Excel will provide a dialog box about the xml schema. Just click “OK”. Then Excel will ask you where to place the data. Leave the default option and click “OK”. You should now see a table containing the urls from your xml sitemap. And yes, you might already see some problems in the list. :)
- Copy the URLs to a Text File
I mentioned earlier that Screaming Frog will only crawl text files with a list of urls in them. In order to achieve this, you should copy all of the urls from column A in your spreadsheet. Then fire up your text editor of choice (mine is Textpad), and paste the urls. Make sure you delete the first row, which contains the heading for the column. Save that file to your computer.
- Unleash the Frog
Next, we’re ready to crawl the urls in the text file you just created. Fire up Screaming Frog and click the “Mode” tab. Select “List”, which enables you to load a text file containing a series of urls. And again, there is now an option to directly crawl a sitemap by entering the url of that sitemap. If you don’t need to download your sitemap, then that’s a great way to go.
- Load The Text File and Start The Crawl
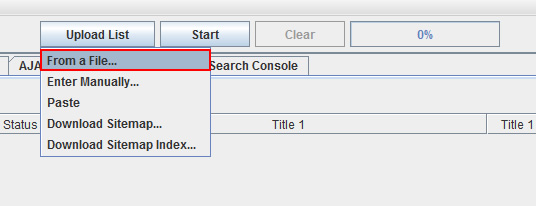
Once you select “List Mode”, then click the Upload List button and select “From a file”. Then select the text file you created. Screaming Frog will load the urls and display them in a window. Once you click OK, the crawl will begin.
- Analyze the Crawl
When the crawl is done, you now have a boatload of data about each url listed in the xml sitemap. The first place I would start is the “Response Codes” tab, which will display the header response codes for each url that was crawled. You can also use the filter dropdown to isolate 404s, 500s, 302s, etc. You might be surprised with what you find.
- Fix The Problems!
Once you analyze the crawl, work with your developer or development team to rectify the problems you identified. The fix sometimes can be handled quickly (in less than a day or two).





Summary – Cleaning Up Dirty Sitemaps
Although XML sitemaps provide an easy way to submit all of your canonical urls to the engines, that ease of setup sometimes leads to serious errors. If you are seeing strange urls getting indexed, or if you are seeing crawl errors for weird or unfamiliar urls, then you might want to check your own sitemaps to see if they are causing a problem. Using this tutorial, you can download and crawl your sitemaps quickly, and then flag any errors you find along the way.
Let’s face it, quick and easy wins are sometimes hard to come by in SEO. But finding xml sitemap errors can be a quick an easy win. And now you know how to find them. Happy crawling.
GG